はじめてのDeepLearning入門(Chainer) 日本語文字認識 4章 [データ拡大による認識精度の改善]
こんにちはリヒトです。3章に続いてDeepLearningチュートリアル4章 データ拡大による認識精度の改善について話します。
認識精度の改善
前回(3章)ではepoch16でのloss0.526がベストスコアでした。ただこれだと活字でも稀に誤認識するなどイマイチです。
しかしこのままこれ以上学習してもtrainのlossだけが下がりtestのlossは上がり続ける「過学習」が起こり認識精度は向上しません。過学習を防いで精度を上げるためにはズバリ学習データを増やしましょう。
オリジナルの学習データを増やす事が理想的ですが、学習データの収集には時間もお金もかかるのでデータ拡大をします。
データ拡大
データ拡大の種類について
1. 回転, 移動, 拡大・縮小, 2値化


2. Elastic Distortion
人工的な歪みを与える事によるデータ拡大。

3. ノイズ
インプルスノイズ・ガウシアンノイズなど

4. 細線化
文字の太さとの認識の依存を解消するための細線化

5. 反転
通常は反転した画像が入力される事はないので、一見悪影響なデータ拡大と思いますが、TTA(テスト時にもデータ拡大をする)の観点から考えて有効です。

実践結果
回転は回転角度と回転軸(3次元的)、移動は移動ピクセル数など乱数を使う事でデータ拡大の組み合わせは無限にあるという事で上の手法を組み合わせて1枚の画像からムゲンの画像を作っていきます。 拡大枚数と結果が以下。
| 拡大枚数 | testのlossベストスコア |
|---|---|
| 10 枚 | 0.526 |
| 100枚 | 0.277 |
| 300枚 | 0.260 |
| 500枚 | 0.237 |
何かあっさりしてますがいい感じです。500枚にも拡大するとデータが重複しないかな?と思いますが結果的にはOK。
ちなみにElastic distortionは見た目が理想的なデータ拡大に見えますが処理に時間がかかったり、過学習の原因になったりするなど実は扱いが難しいです(あくまで経験談)
ひたすら拡大してテスト
500枚でも順調に精度が上がってる(ロスが下がっている)ので、次は3500枚に拡大してみました。(ただしメモリ的な意味でも処理時間的な意味でも(私のPC的に)限界があるので、「あ」「い」「う」「え」「お」の5枚だけに限定。)
('epoch', 1)
train mean loss=0.167535232874, accuracy=0.937596153205
test mean loss=0.23016545952, accuracy=0.914285708447
('epoch', 2)
train mean loss=0.0582337708299, accuracy=0.979920332723
test mean loss=0.132406316127, accuracy=0.955102039843
('epoch', 3)
train mean loss=0.042050985039, accuracy=0.985620883214
test mean loss=0.0967423064653, accuracy=0.959183678335
('epoch', 4)
train mean loss=0.0344518882785, accuracy=0.98846154267
test mean loss=0.0579228501539, accuracy=0.983673472794
結果はこんな感じ。 epoch4でlossが0.057まで下がっています。 3章にあった通りloss0.237のモデルで何となく手書きひらがなが認識出来たので今回は期待出来そうです。 そこで手元で適当にひらがなを50枚書いて精度をテスト。

今回はテスト時に30枚にデータ拡大してから認識結果を評価しています。 (この"30枚"には特に理由がある訳ではありません)
$ python AIUEONN_predictor.py --model loss0057model --img ../testAIUEO/o0.png init done 候補 ニューロン番号:4, Unicode:304a, ひらがな:お . .(中略) . 候補 ニューロン番号:4, Unicode:304a, ひらがな:お 候補 ニューロン番号:4, Unicode:304a, ひらがな:お 候補 ニューロン番号:3, Unicode:3048, ひらがな:え 候補 ニューロン番号:4, Unicode:304a, ひらがな:お **最終判断 ニューロン番号:4, Unicode:304a, ひらがな:お**
OKです。
結果
50枚中46枚正答。4枚ミスで精度92%となりました! ちなみにミスしたものはこちらの4枚だけ。
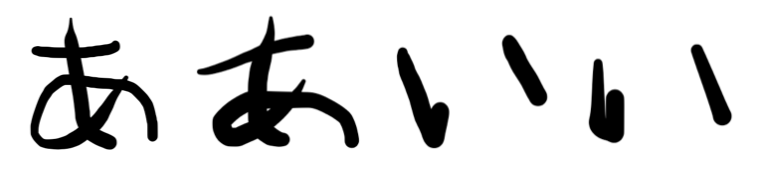
「あ」の方は大分字が汚いですね(汗;
上手くいったものの一部

手前味噌のテストデータセットなので表現が難しいですが、まぁまぁ良い精度が出ています。 活字中心の学習データで手書き文字にも応用性があるという事でDeepLearningの可能性を感じます。 4章はここで終了です。次5章ではHi-Kingさんのブログも参考にニューラルネットの基本から学んで行きたいと思います。
はじめてのDeepLearning入門(Chainer) 日本語文字認識 3章 [モデルを利用した文字認識]
こんにちはリヒトです。こちらに続いてDeepLearningチュートリアル3章 モデルを利用した文字認識について説明します。
準備
2章のDeepLearningの機械学習によって生成されたmodel16を使います。 まずは平仮名の画像を用意しましょう。本当は学習に使ったデータに無いフォントの物が良いですが探すのも難しいのでテキトウに準備します。
探すのが面倒な人は下の画像をダウンロードして使って下さい。(OneNoteで「あ」と書いて画像で切り出した)

認識
先ほどの画像「あ」(a.png)をmodel16とと同じディレクトリに置いて、
ターミナルから以下のコマンドを入力します
python hiraganaNN_predictor.py --img a.png --model model16
すると出力に
候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:10, Unicode:304b, ひらがな:か 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:78, Unicode:308f, ひらがな:わ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ **最終判断 ニューロン番号:1, Unicode:3042, ひらがな:あ**
と予測結果が出て来ました。 候補の中に「か」とか「わ」があるものの、最終判断の出力は「あ」なので認識成功です。 この候補というのは1枚の画像を複数(14枚)に拡大した時の各々の認識結果です。 最終判断というのは各々の認識結果を平均したものです。

これは1枚の画像から判断するのでは無く、色んな角度から判断する事で認識精度を上げるというTTA(Test Time Argumentation) という手法と同じコンセプトです。 他の認識も試してみます。
a2.png
 認識
認識
python hiraganaNN_predictor.py --img a2.png --model model16
結果
**最終判断 ニューロン番号:1, Unicode:3042, ひらがな:あ**
a3.png

認識
python hiraganaNN_predictor.py --img a2.png --model model16
結果
**最終判断 ニューロン番号:1, Unicode:3042, ひらがな:あ**
OKです。
手書きひらがな文字認識
認識正解という事でもう少し難しい認識に挑戦してみましょう。 手書きの「あ」を認識してみましょう。

正直無茶振りですが、まぁやるだけやってみましょう。
python hiraganaNN_predictor.py --img a_tegaki.png --model model16
で認識開始
候補 ニューロン番号:71, Unicode:3088, ひらがな:よ 候補 ニューロン番号:30, Unicode:305f, ひらがな:た 候補 ニューロン番号:71, Unicode:3088, ひらがな:よ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:24, Unicode:3059, ひらがな:す 候補 ニューロン番号:71, Unicode:3088, ひらがな:よ 候補 ニューロン番号:30, Unicode:305f, ひらがな:た 候補 ニューロン番号:24, Unicode:3059, ひらがな:す 候補 ニューロン番号:32, Unicode:3061, ひらがな:ち 候補 ニューロン番号:32, Unicode:3061, ひらがな:ち 候補 ニューロン番号:24, Unicode:3059, ひらがな:す 候補 ニューロン番号:30, Unicode:305f, ひらがな:た 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ **最終判断 ニューロン番号:32, Unicode:3061, ひらがな:ち**
失敗です!笑 候補にはちょいちょい「あ」がありますが、最終判断「ち」なのでダメでした。 まぁmodel16はlossが0.526だし、活字で学習したのでこんなもんです。 ただこの後の章の改善策を幾つか施してlossを0.237まで下げたモデルで試すと
python hiraganaNN_predictor.py --img a2.png --model loss237model
候補 ニューロン番号:30, Unicode:305f, ひらがな:た 候補 ニューロン番号:52, Unicode:3075, ひらがな:ふ 候補 ニューロン番号:52, Unicode:3075, ひらがな:ふ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:32, Unicode:3061, ひらがな:ち 候補 ニューロン番号:71, Unicode:3088, ひらがな:よ 候補 ニューロン番号:52, Unicode:3075, ひらがな:ふ 候補 ニューロン番号:9, Unicode:304a, ひらがな:お 候補 ニューロン番号:52, Unicode:3075, ひらがな:ふ 候補 ニューロン番号:9, Unicode:304a, ひらがな:お 候補 ニューロン番号:1, Unicode:3042, ひらがな:あ 候補 ニューロン番号:9, Unicode:304a, ひらがな:お 候補 ニューロン番号:10, Unicode:304b, ひらがな:か **最終判断 ニューロン番号:1, Unicode:3042, ひらがな:あ**
(ぎりぎりですが)正しく認識出来てます! 基本的には活字を学習データにして機械学習して来ましたが、手書きも少しは認識できるモデルになっています。 候補がちょいちょい間違えて認識しているのでやはりTTAの有用性が伺えます。
ちなみに 候補に「あ」が3つで「ふ」が4つなのに何で最終判断「あ」なの?と思った方、するどい! ただここでは単純な多数決をしている訳ではありません。より確信を持って判断している結果を考慮しています。 つまり4つの「ふ」は全部あやふやで予測していたのに対して3つの「あ」は確信を持っていたという事で、最終判断は「あ」と判断出来ている訳です。
ソースコード概要
最後にソースコードの概要説明です。大部分は機械学習に使ったhiraganaNN.pyと同じです。
def forward(x_data, train=False):
x = chainer.Variable(x_data, volatile=not train)
h = F.max_pooling_2d(F.relu(model.bn1(model.conv1(x))), 2)
h = F.max_pooling_2d(F.relu(model.bn2(model.conv2(h))), 2)
h = F.max_pooling_2d(F.relu(model.conv3(h)), 2)
h = F.dropout(F.relu(model.fl4(h)), train=train)
y = model.fl5(h)
return y.data
ここはDeepLearningのニューラルネット構造でhiraganaNN.pyのfowardと同じ構造をしている必要があります。
src = cv2.imread(args.img, 0)
src = cv2.copyMakeBorder(
src, 20, 20, 20, 20, cv2.BORDER_CONSTANT, value=255)
src = cv2.resize(src, (IMGSIZE, IMGSIZE))
入力画像の読み込みと64*64の画像サイズにリサイズ。 また画像に20ピクセルずつ余白をつけています。今のままのモデルでは余白が適切な量でないと上手く認識出来ません。
for x in xrange(0, 14):
dst = dargs.argumentation([2, 3])
ret, dst = cv2.threshold(dst,
23,
255,
cv2.THRESH_BINARY)
#画像確認用
#cv2.imshow('ARGUMENTATED', dst)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
xtest = np.array(dst).astype(np.float32).reshape(
(1, 1, IMGSIZE, IMGSIZE)) / 255
if result is None:
result = forward(xtest)
else:
result = result + forward(xtest)
入力画像をデータ拡大して、2値化してから、画素値を0-1に正規化し、foward関数で予測しています。
tmp = np.argmax(forward(xtest))
for strunicode, number in unicode2number.iteritems():
if number == tmp:
hiragana = unichr(int(strunicode, 16))
print '候補 ニューロン番号:{0}, Unicode:{1}, ひらがな:{2}'.format(number, strunicode, hiragana.encode('utf_8'))
ニューラルネットの認識結果(0-82の番号)をunicodeに変換し、ひらがなとして出力しています。 3章はここで終了です。 4章では1枚の画像を3500枚に拡大して精度を見てみます。
はじめてのDeepLearning入門(Chainer) 日本語文字認識 2章[機械学習によるモデルの生成]
こんにちはリヒトです。こちらに続いてDeepLearningチュートリアル2章 機械学習によるDeepLearning予測モデルの生成について説明します。 ニューラルネットが具体的にどの様に機械学習していくかは後の章にまとめて説明するとして、 ここでは実践的な使い方を紹介します。
準備
まずはこちらのGithubからソースコードをダウンロードしてhiraganaNN.py以下全てを先ほどの画像データセットと同じディレクトリに置きます。 2章ではhiraganaNN.py, dataArgs.py, hiragana_unicode.csvを使います。
実行
ターミナル(コマンドプロンプト)でHIRAGANA_NNディレクトリまで移動してから
python hiraganaNN.py
で起動します。
これでDeepLearningによる機械学習がスタートするのですが学習に時間がかかるので待っている間に少し解説をします。 HIRAGANA_NNディレクトリの中には平仮名それぞれにディレクトリ分けされた画像(110*110ピクセル)が格納されています。 例えば305eディレクトリには平仮名の「ぞ」の画像が色んなフォント・手書きで以下の様に登録されています。
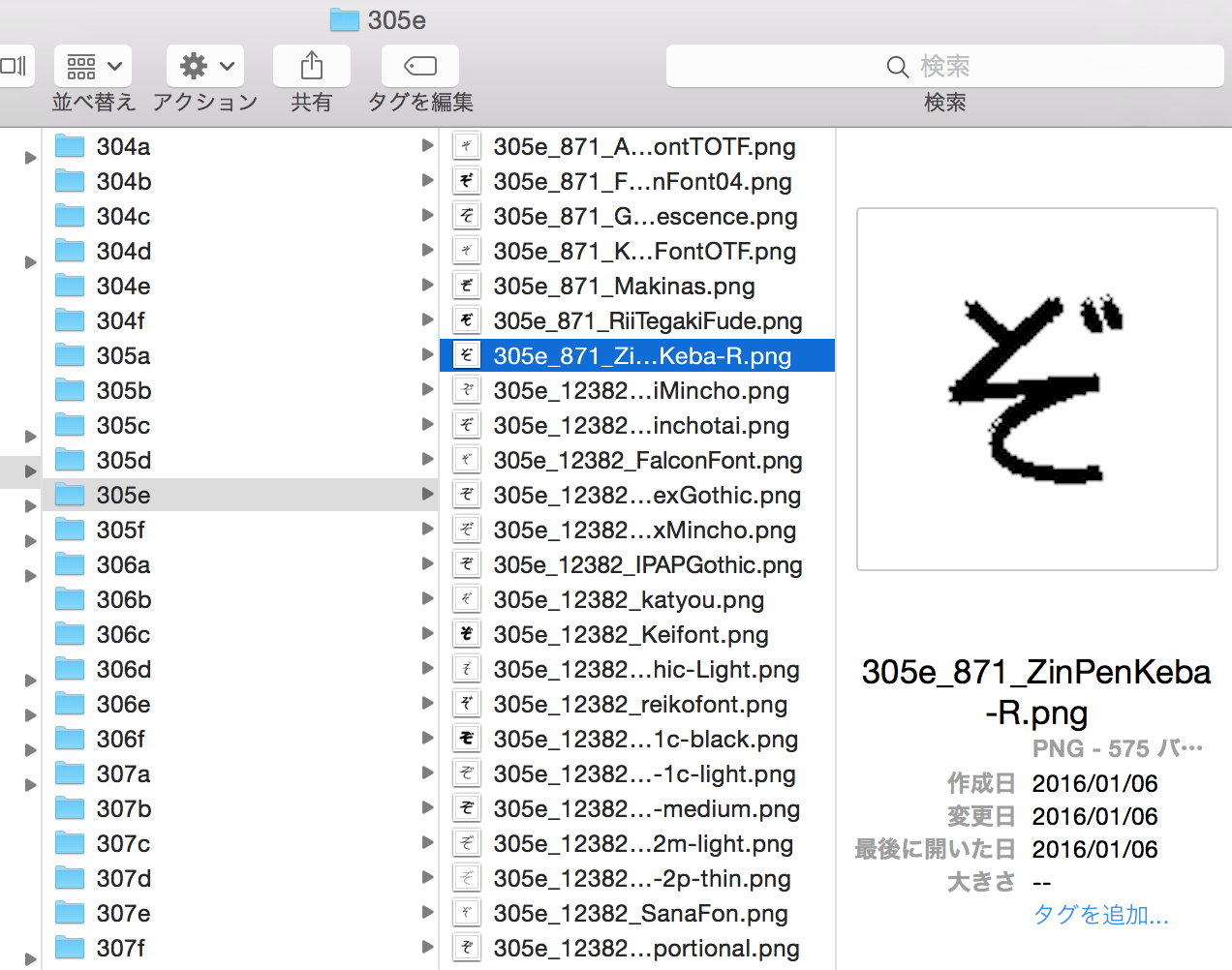
機械学習の目的は色んな「ぞ」の画像から「ぞ」って一般的にはどんな形をしたもの?というのを学習しようという試みです。つまりこれらは「ぞ」なのだから(学習)

これは「ぞ」だよね?(識別・予想・認識とか言われる)という事がしたい訳です。

簡単な様に聞こえますが機械は単純なので人間では思いもよらないミスをしたりします。 例えば上を「ぞ」を学習した。だから下は「ぞ」ではない!キッパリ

(なぜなら少し傾いているから) こういった行き過ぎた学習(上の「ぞ」以外は「ぞ」と認められない)によるミス(汎用性の劣化)を「過学習」と言います。 また文字の色・濃度など認識する上で本来関係の無い所で学習が難しくなっている学習効率の悪化なども性能劣化の原因です。

過学習や学習効率の悪化などの性能劣化を避けるための「前処理」を行います。 前処理は様々ですがデータ拡大(回転・移動・弾性歪み・ノイズなど)(色んな「ぞ」を学習しておけば何が来ても大丈夫!)や、

問題を単純にして学習効率をアップさせるデータ正規化(グレースケール化、白色化、バッチ正規化など)などがその一例です。
ソースコードの概要
1行目から順に
unicode2number = {}
import csv
train_f = open('./hiragana_unicode.csv', 'rb')
train_reader = csv.reader(train_f)
train_row = train_reader
hiragana_unicode_list = []
counter = 0
for row in train_reader:
for e in row:
unicode2number[e] = counter
counter = counter + 1
ここでは各平仮名に番号付けをしています。unicodeが304a(お)のものは0番、304b(か)のものは1番という具合です。 次に
files = os.listdir('./')
for file in files:
if len(file) == 4:
# 平仮名ディレクトリ
_unicode = file
imgs = os.listdir('./' + _unicode + '/')
counter = 0
for img in imgs:
if img.find('.png') > -1:
if len(imgs) - counter != 1:
...
ここでは入力データ(学習データ)としての画像を読み込んでいます。各ディレクトリの一番最後の画像だけテスト用に読み込みます。 読み込み時には
x_train.append(src) y_train.append(unicode2number[_unicode])
という風にx_train(x_test)には画像データ、y_train(y_test)には正解のラベル(0-83)を格納して行きます。 1枚の入力データの画像に対してデータ拡大を施して行くのが以下の部分で
for x in xrange(1, 10):
dst = dargs.argumentation([2, 3])
ret, dst = cv2.threshold(
dst, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
x_train.append(dst)
y_train.append(unicode2number[_unicode])
ここではランダムに移動と回転を施して10枚に拡大しています。 dargs.argumentation([2, 3])の2, 3は凄まじく分かり辛いですが順に2:回転(3次元的な奥行きを持った回転)と3:移動で、回転処理を施した後に移動処理を施しています。 各ディレクトリの
次は
x_train = np.array(x_train).astype(np.float32).reshape(
(len(x_train), 1, IMGSIZE, IMGSIZE)) / 255
y_train = np.array(y_train).astype(np.int32)
グレースケールの画像は0-255の画素値を持っていますがこれを255で割る事で0-1の値に正規化しています。この処理によって学習効率が向上します。
以上は学習データ用(x_train, y_train)の準備でしたがテスト用(x_test, y_test)の準備も同様に行います。 ここでは各ディレクトリにある最後の1枚をテスト用として読み込んで機械学習しているモデルの精度を検証します。 テスト用の画像も拡大して読み込んでいますが、ここら辺の理由は7章あたりに書きます。
以降はDeepLearningの具体的な構造についてなので後々の章に説明をまとめます。
学習結果
そうこうしている内にターミナルに機械学習の進捗が出てきました。
('epoch', 1)
COMPUTING...
train mean loss=3.53368299341, accuracy=0.161205981514
test mean loss=1.92266467359, accuracy=0.506097565337
('epoch', 2)
COMPUTING...
train mean loss=1.66657279936, accuracy=0.518463188454
test mean loss=1.0855880198, accuracy=0.701219529277
.
.(warningとかも出てきますが取り敢えず無視でOK)
('epoch', 16)
COMPUTING...
train mean loss=0.198548029516, accuracy=0.932177149753
test mean loss=0.526535278777, accuracy=0.844512195849
.
.
('epoch', 23)
COMPUTING...
train mean loss=0.135178960405, accuracy=0.954375654268
test mean loss=0.686121761981, accuracy=0.814024389154
lossというのはDeepLearningよって予測された出力と正解との誤差と思っていて下さい。accuracyは正答率です 機械学習ではtestデータのlossを下げる事が目標です。
学習が進むに連れて、train, testのlossが下がって行きますがepoch16を境にtrainのlossは下がるが testのlossは増えていく過学習の傾向がみられます。 こうなったら学習は限界という事で終了。取り敢えず今回のモデルではepoch16のtest loss=0.526が最も良い結果を出しています。(この精度向上への取り組みは後の章)
ソースコードと同じディレクトリに各epochのDeepLearningの学習結果が保存されているので、 最も結果の良かった'model16'というファイルを取っておいて下さい。(他のモデルファイルは消してもOKです)
次回の第3章はこのモデルを利用した実際の予測を行います。
はじめてのDeepLearning入門(Chainer) 日本語文字認識 1章[環境構築]
こんにちはリヒトです。 環境研究所で販売されている日本語文字認識データセットを入手したので、データセットを活用したDeepLearning初学者のためのチュートリアルを公開します。 日本語の文字認識エンジンの開発にトライします。
以下の画像を見てもわかる様に、ゲシュタルト崩壊請け合いなチュートリアルですが、めげずに頑張っていきたいと思います。

なおこの記事は ・DeepLearningをはじめたい! ・mnistの数字認識以外のチュートリアルをやりたい! ・DeepLearning関連技術について学びたい! ・自分で日本語OCRの開発をしたい!
という方々に向けて書いています。 以下のアウトラインで説明します。
| 章 | タイトル |
|---|---|
| 1章 | chainerをベースにしたDeepLearning環境の構築 |
| 2章 | 機械学習によるDeepLearning予測モデルの作成 |
| 3章 | モデルを利用した文字認識 |
| 4章 | データ拡大による認識精度の改善 |
| 5章 | ニューラルネット入門とソースコードの解説 |
| 6章 | Optimizerの選択による学習効率の改善 |
| 7章 | TTA, BatchNormalizationによる学習効率の改善 |
DeepLearningは完全に初めて、という方はとにかく動く物を見て欲しいので4章目までトライして下さい。 5章以下はDeepLearningについてもう一歩詳しく知りたいという人向けです。
はじめに
なぜchainer?
chainerは国産OSSです。何より使いやすいし、理解しやすいしGoogle Groupでchainerに関する質問をしてもすぐに無料でレスポンスしてくれるなど最高。
環境
本編はMacを前提にお話しますが、随時Windowsに合わせてそれぞれ説明(違いは環境準備だけですが)します。 ・マシンスペック:メモリ4GB以上 ・Python2.7系, pipがインストールされていること
環境準備(Mac)
ターミナルで
sudo pip install chainer
を入力し、chainer1.6.0, filelock2.0.5, nose1.3.7, numpy1.10.4, protobuf2.6.1を一括インストールします。
sudo pip install scipy
を入力し、scipy0.17.0をインストールします。
またこちらの記事を参考にOpencv2.4.X系をインストールして下さい。
環境準備(Windows)
pip install chainer
を入力し、chainer1.6.0, filelock2.0.5, nose1.3.7, numpy1.10.4, protobuf2.6.1を一括インストールします。
pip install scipy
を入力し、scipy0.17.0をインストールします。必要に応じてコマンドプロンプトを管理者モードで起動してください。 またこちらの記事を参考にOpencv2.4.X系をインストールして下さい。
データの準備(Mac, Windows)
環境研のウェブサイトから平仮名データセットを購入(1000円)してダウンロードします。 デスクトップに"HIRAGANA_NN"というディレクトリを作成してその中に解凍します。
-DESKTOP -HIRAGANA_NN -304a -304b ・ ・ (参考)以下の画像の様になっていればOKです。
なお304aなどのディレクトリはそれぞれの平仮名のUnicodeを示しており、中身は以下の様になっています

これで準備が完了です。 次2章から機械学習に進んで行きたいと思います!